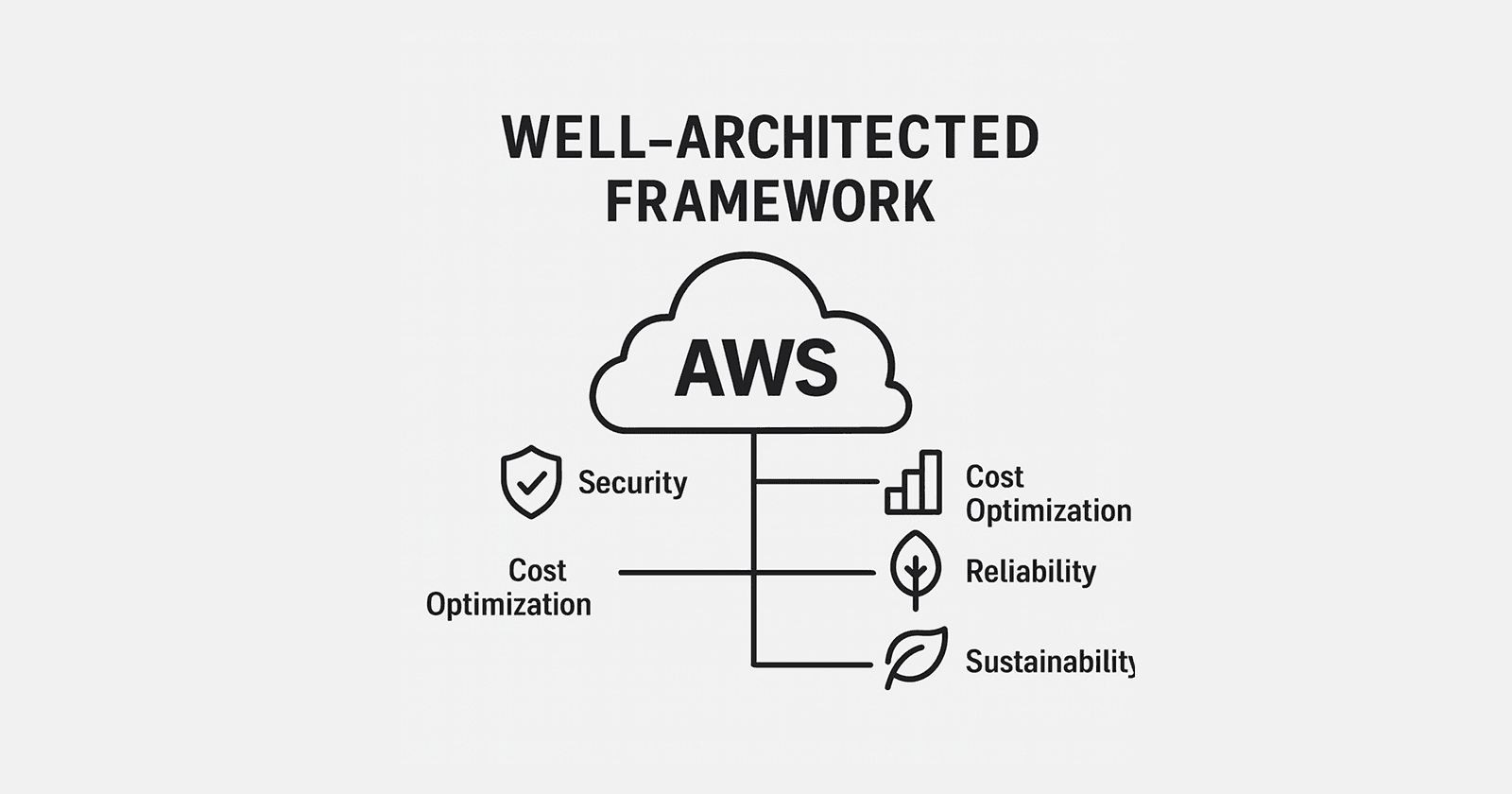
Well-Architected Framework
I'm a full stack developer and cyber security entushiast with over 4 years of experience, and a student who spends most all of his free time playing capture the flags.
O Well-Architected Framework é um conjunto de boas práticas recomendadas pela a AWS para criar e projetar arquiteturas que contenham excelência operacional, segurança, confiabilidade, eficiência de performace, otimização de custos e sustentabilidade. Este framework é utilizado depois que a empresa já passou pelo o processo de adoção da nuvem na empresa, ou seja, já foi definido que vão utilizar os serviços AWS, agora basta usar das melhores práticas para fazer essa implementação da maneira mais correta possível. Neste artigo, será apresentado os 6 pilares do Well-Architected de maneira resumida como forma de conhecimento para o exame CLF-C02.
Excelência operacional
A excelência operacional define como operar, monitorar, automatizar e melhorar uma aplicação depois que está em produção. De modo geral, este pilar foca em garantir que as operações do sistema seja organizada, observável, automatizada e capaz de lidar com problemas sem causar impacto grande no negócio.
Operar
Está parte serve para garantir que uma aplicação continue saudável e estável. Operar a sua aplicação inclui também todo o conceito de monitorar, automatizar, detectar problemas, fazer deploys seguros e previsíveis, responder a incidentes e gerenciar mudanças com segurança. Ou seja, de modo geral é tudo que você faz na excelência operacional para manter a sua aplicação em pé.
Monitorar
O monitoramento dentro da excelência operacional ajuda a entender tudo que está acontecendo dentro de uma aplicação. É nesta etapa que será coletado os logs, métricas e traces para entender o comportamento do sistema, identificar gargalos, acompanhar desempenho e perceber qualquer problema antes do usuário.
Automatizar
A automação é tirar o trabalho manual da operação. É substituir tarefas repetitivas e demoradas por processos automáticos. Isto inclui backups, rotinas de limpeza, escalonamento automático, correções automáticas, patching, verificações de saúde e várias outras atividades.
Melhorar uma aplicação depois que está em produção
Está etapa é melhorar a aplicação depois que ela está em produção e analisar o que aconteceu, aprender com problemas e ajudar a operação para deixar tudo mais fluído no momento de fazer atualizações.
Segurança
A segurança garante que uma aplicação, os dados e o acesso estejam protegidos contra o uso indevido, ataques e erros humanos sem atrapalhar o funcionamento do sistema. Este pilar funciona em torno de seis bases:
| Fundamentos | Significado | Exemplo |
| Fundamentos de Identidade e acesso | Controla quem pode fazer o quê na AWS | IAM Roles e Policies, MFA, IAM Identity Center, acesso mínimo necessário (least privilege) |
| Rastreabilidade | Registrar atividades, eventos e tudo o que acontece no ambiente | CloudTrail, AWS Config, Cloud Watch Logs, Event Bridge para alertas |
| Proteção de infraestrutura | Protege a camada de rede e os recursos que rodam nela | Security Groups, NACLs, VPC, AWS Shield, WAF e segmentação de rede. |
| Proteção de Dados | Garantir privacidade, integridade e disponibilidade dos dados | KMS para criptografia, Secrets Manager, S3 Encryption, RDS snapshots |
| Gerenciamento de Incidentes | Preparar, Detectar e responder rapidamente a incidentes de segurança | Playbooks, AWS GuardDuty, Security Hub, automações de resposta com Lambda |
| Melhoria contínua | Revisar e evoluir constantemente as práticas de segurança | Auditorias periódicas, simulações com o IAM Access Analyzer e atualizações. |
Confiabilidade
A confiabilidade garante que o sistema funcione corretamente, tolere falhas e se recupere rapidamente quando algo dá errado. Este pilar é composto de três sub-pilares sendo eles:
| Parte da Confiabilidade | O que significa | Exemplos |
| Fundamentos da Confiabilidade | São pré-requisitos para que o ambiente seja resiliente e não quebre por limites, má configuração ou falta de planejamento. | Gerenciar quotas, planejar CIDR da VPC, Service Quotas, Systems Manager Change Manager, AWS Organizations, IAM bem estruturado. |
| Arquitetura Resiliente | É construir workloads que continuem funcionando mesmo quando alguma parte falhar. Evita pontos únicos de falha e utiliza redundância. | Multi-AZ, Auto Scaling, Load Balancer, RDS Multi-AZ, DynamoDB com replicação, arquitetura sem servidor (Lambda), SQS para desacoplar. |
| Recuperação (Recovery/DR) | Estratégias para restaurar o sistema rápido quando ocorre falha, desastre ou perda de dados. | Backup & Restore, Snapshots, AWS Backup, S3 CRR, Aurora Global Database, Route 53 failover, Pilot Light, Warm Standby, Multi-Site |
Eficiência de performace
Este pilar foca no uso de recursos corretos, de forma que uma aplicação consiga performar bem conforme cresce, sem disperdício ou gargalos. Este é composto por quatro sub-pilares:
| Fundamento | O que significa | Exemplo |
| Selection (Escolha de recursos) | Escolher os melhores serviços, tipos de instância e soluções para maximizar a performance desde o design. | EC2 Graviton, tipos de instância otimizados (CPU/Mem/GPU), Aurora vs RDS, DynamoDB, Lambda, EBS gp3, S3 Standard vs Glacier. |
| Review (Revisão constante) | Reavaliar periodicamente se os recursos usados ainda são os melhores conforme a AWS lança novidades. | Migrar para instâncias mais novas, adotar Graviton, trocar gp2→gp3, migrar para Aurora, usar serviços mais eficientes lançados recentemente. |
| Monitoring (Monitoramento de performance) | Acompanhar métricas e detectar gargalos antes que afetem o usuário. | CloudWatch Metrics, X-Ray, métricas de CPU/Memória/IOPS/Latência, alarmes, logs e dashboards. |
| Tradeoffs (Trocas para performance) | Fazer ajustes que aumentam a performance mesmo que custem mais ou adicionem complexidade. | ElastiCache/CloudFront para cache, aumentar memória da Lambda, read replicas no RDS, instâncias maiores, paralelização com SQS/Kinesis. |
Otimização de custos
A otmização de custos é sobre gastar apenas o necessário para rodar uma aplicação, eliminando disperdícios e escolhendo recursos que entregam o melhor custo-benefício. Este pilar é composto por cinco fundamentos:
| Parte da Otimização de Custos | O que significa | Exemplo |
| Cost-Effective Resources | Escolher os recursos mais baratos que ainda entregam a performance necessária. | EC2 Graviton, EC2 Spot, Aurora Serverless, EBS gp3, S3 Intelligent-Tiering, DynamoDB On-Demand. |
| Expenditure Awareness (Visibilidade dos custos) | Ter clareza total sobre quem está gastando e onde. | Cost Explorer, AWS Budgets, CUR, Tags de custo, dashboards. |
| Cost Management (Controle ativo) | Tomar ações práticas para limitar e gerenciar gastos. | Budgets com alertas, quotas, SCP bloqueando serviços caros, desligar ambientes de dev, bloquear regiões. |
| Elasticity (Elasticidade) | Escalar automaticamente para não pagar por capacidade ociosa. | Auto Scaling, Lambda pay-per-use, Aurora Serverless, DynamoDB On-Demand, Kinesis On-Demand. |
| Optimizing Over Time (Melhoria contínua) | Revisar periodicamente o ambiente para remover desperdícios e ajustar recursos. | Rightsizing, apagar EBS órfãos, limpar snapshots antigos, Compute Optimizer, reduzir tamanho de RDS, revisar S3 Storage Classes. |
Sustentabilidade
Este pilar visa reduzir o impacto ambiental da aplicação, usando a nuvem de forma mais eficiente, com menos desperdício e promovendo práticas que economizam energia e recursos.
| Fundamento | O que significa | Exemplos |
| Region Selection (Escolha da região) | Escolher regiões com maior uso de energia renovável e menor impacto ambiental. | Regiões com energia limpa, dados de carbono da AWS, regiões com resfriamento natural. |
| Software Efficiency (Eficiência do software) | Otimizar o código para consumir menos CPU, memória e operações desnecessárias. | Queries otimizadas, payloads menores, algoritmos mais eficientes, reduzir chamadas redundantes. |
| Hardware Efficiency (Eficiência do hardware) | Usar hardware mais eficiente energeticamente e arquiteturas otimizadas. | EC2 Graviton, Lambda, Aurora, instâncias modernas com melhor performance por watt. |
| Data Management (Gerenciamento de dados) | Reduzir, otimizar e mover dados para camadas mais eficientes. | S3 Intelligent-Tiering, expiração de logs, compressão, deduplicação, classes de storage eficientes. |
| Workload Efficiency (Eficiência da carga) | Evitar recursos ociosos e usar arquiteturas elásticas e sob demanda. | Serverless, Auto Scaling, jobs sob demanda, paralelização eficiente. |
| Development & Deployment (Ciclo sustentável) | Reduzir desperdício no ciclo de desenvolvimento e evitar retrabalho. | Pipelines otimizados, testes eficientes, ambientes temporários, IaC bem estruturado. |
Conclusão
Neste artigo foi abordado os 6 pilares do AWS Well-Architected de uma forma bem abrangente, a ideia é ter uma base sólida para se preparar para o exame do CLF-C02. Caso tenha o ajudado, considere compartilhar com alguém que esteja com a ideia de se certificar com o exame.